Improving Factuality and Reasoning in Language Models through Multiagent Debate
Abstract
Large language models (LLMs) have demonstrated remarkable capabilities in language generation, understanding, and few-shot learning in recent years. An extensive body of work has explored how their performance may be further improved through the tools of prompting, ranging from verification, self-consistency, or intermediate scratchpads. In this paper, we present a complementary approach to improve language responses where multiple language model instances propose and debate their individual responses and reasoning processes over multiple rounds to arrive at a common final answer. Our findings indicate that this approach significantly enhances mathematical and strategic reasoning across a number of tasks. We also demonstrate that our approach improves the factual validity of generated content, reducing fallacious answers and hallucinations that contemporary models are prone to. Our approach may be directly applied to existing black-box models and uses identical procedure and prompts for all tasks we investigate. Overall, our findings suggest that such "society of minds" approach has the potential to significantly advance the capabilities of LLMs and pave the way for further breakthroughs in language generation and understanding.
Results
Existing approaches towards improving language models have primarily focused on improving the performance of a single language generator. We illustrate how we may treat different instances of the same language models as a "multiagent society", where individual language model generate and critique the language generations of other instances of the language model. We find that the final answer generated after such a procedure is both more factually accurate and solves reasoning questions more accurately. We illustrate below the quantitative difference between multiagent debate and single agent generation on different domains in reasoning and factual validity.
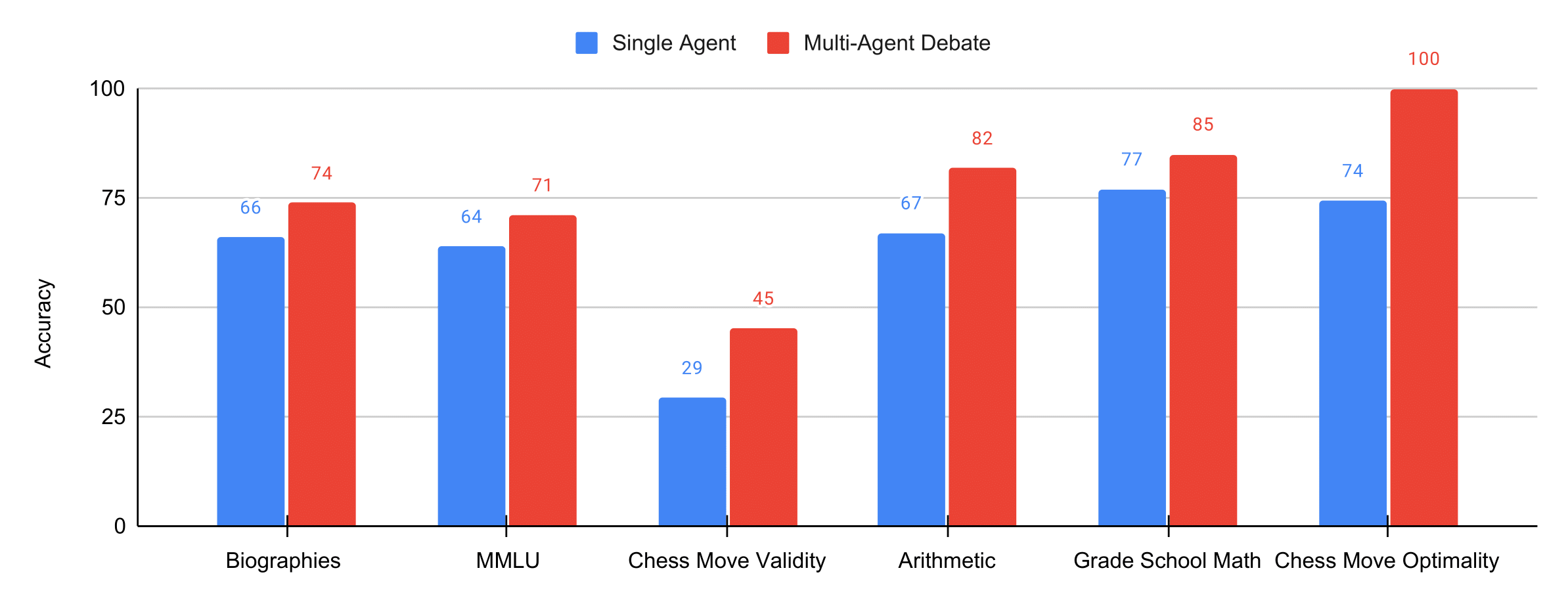
Multiagent Debate Improves Reasoning and Factual Accuracy. Accuracy of traditional inference and our multi-agent debate over six benchmarks (chess move optimality reported as a normalized score)
Performance with More Agents and Rounds of Debate
Throughout the experiments in the paper, we used a total of 3 language models agents which debate for a total of two arounds, due to computational cost. However, the underlying performance of multiagent debate can be substantially improved by either using more agents or by having more of rounds of debate. Below, we report the accuracy of solving arithmetic expressions as these individual factors are varied.
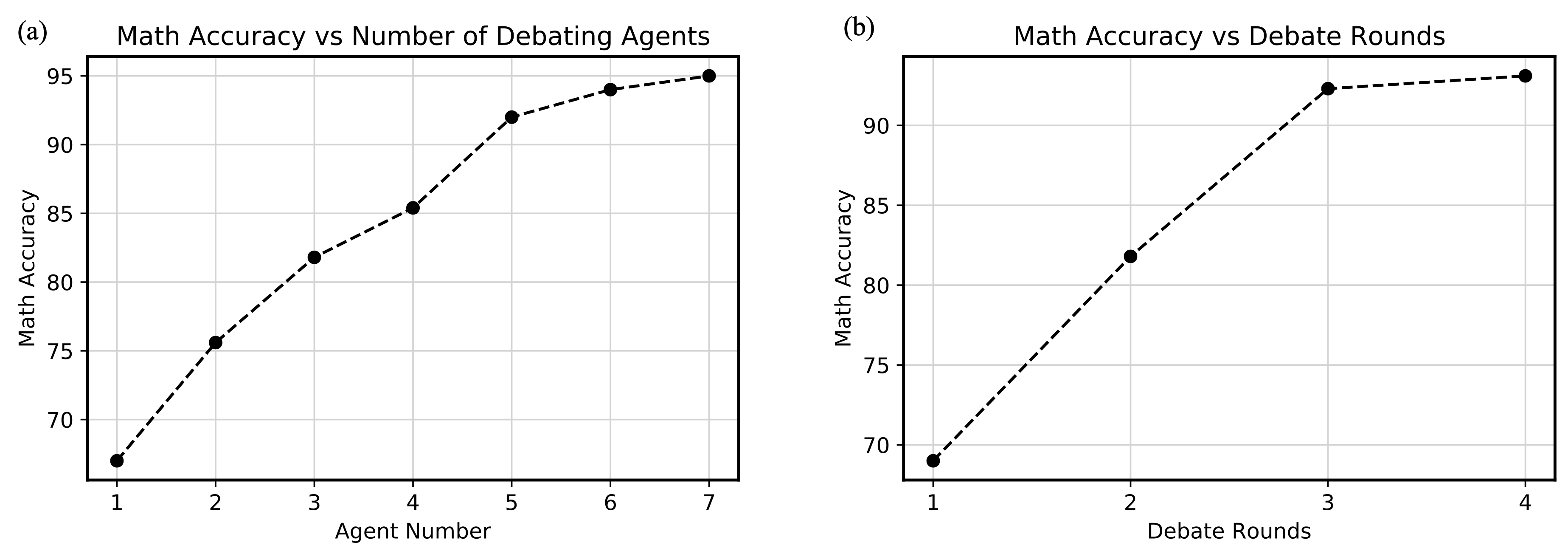
(a) Performance with Increased Agents. Arithmetic performance improves as the number of underlying agents involved in debate increases. (b) Performance with Increased Rounds. Arithmetic performance improves as the number of rounds of underlying debate increases.
Debate Between chatGPT and Bard
While we mainly study multiagent debate across multiple instances of the same language model, multiagent debate can also be used to combine different lanuage models together. This enables the strengths of one model to enable better performance in another. Below, we illustrate how a combination of both ChatGPT and Bard can be used together to solve a difficult Grade School Math problem.
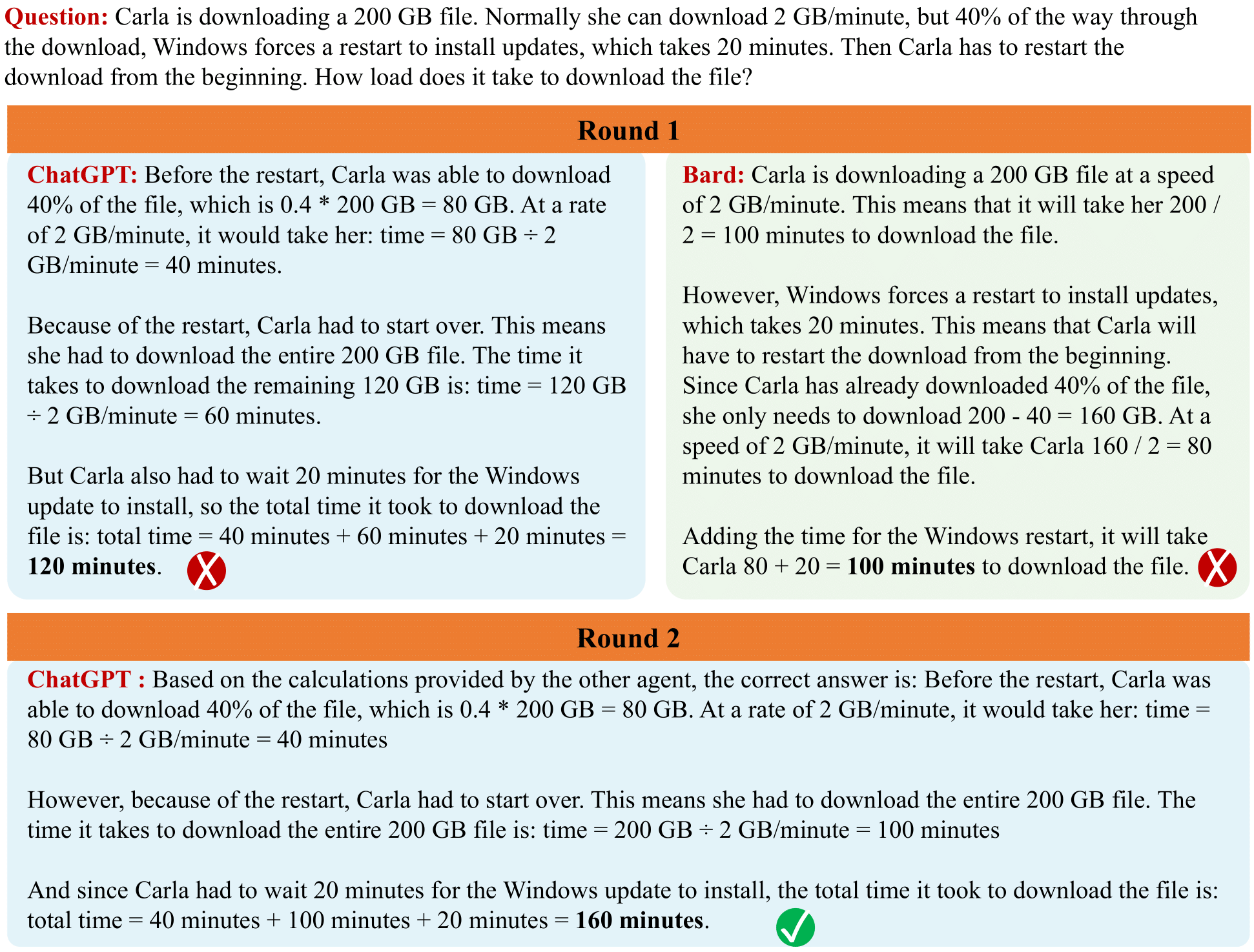
Debate Between ChatGPT and Bard. Illustration of debate between different models. While both models generate incorrect responses to the initial GSM8K problem, debate between the models enables them to generate the correct final answer.


